
第六章 图
图主要讨论邻接矩阵和邻接表两种实现方式。然后从遍历的角度介绍将图转换为树的典型方法,包括广度优先搜索和深度优先搜索。进而,分别以拓扑排序和双连通域分解为例,介绍利用基本数据结构并基于遍历模式,设计图算法的主要方法。最后,从“数据结构决定遍历次序”的观点出发,将所有遍历算法概括并统一为最佳优先遍历这一模式。 如此,我们不仅能够更加准确和深刻地理解不同图算法之间的共性与联系,更可以学会通过选择和改进数据结构,高效地设计并实现各种图算法这也是本章的重点与精髓。
6.1 概述
图
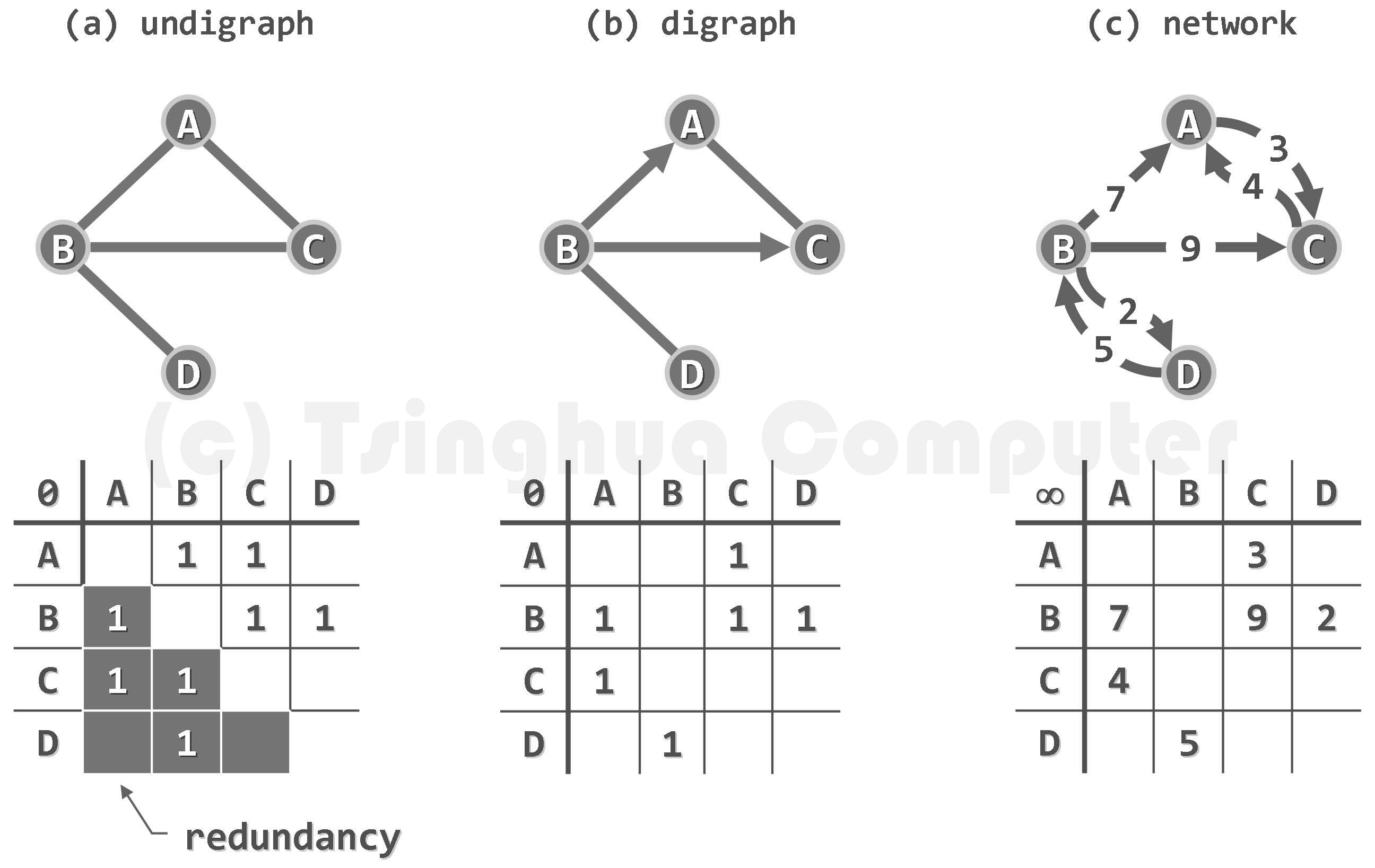
图,定义为G=(V,E)。其中集合V中的元素称为顶点,集合E中的元素分别对应于V中的某一对顶点(u,v),表示它们之间存在某种关系,亦称作边。
无向图、有向图以及混合图
同时包含有向边和无向边的,称作混合图。
度
在无向图中,与顶点v关联的边数,称作v的度数。 对于有向图中的有向边e=(u,v),e称作u的出边,v的入边。 v的出边总数称作其出度,入边总数称作其入度。
带权网络
复杂度
问题的输入规模,应该以顶点数与边数的总和(n+e)来度量。 e=O(n^2)
6.2 抽象数据类型

6.3 邻接矩阵
原理
邻接矩阵是图ADT最基本的实现方式,使用方阵A[n][n]表示由n个顶点构成的图,其中每个单元,各自负责描述一对顶点之间可能存在的邻接关系,故此得名。
时间性能
然而,这种方法并非完美无缺。其不足主要体现在,顶点的动态操作接口均十分耗时。为了插入新的顶点,顶点集向量V[] 需要添加一个元素;边集向量E[][]也需要增加一行,且每行都需要添加一个元素。顶点删除操作,亦与此类似。不难看出,这些恰恰也是向量结构固有的不足。好在通常的算法中,顶点的动态操作远少于其它操作。而且,即便计入向量扩容的代价,就分摊意义而言,单次操作的耗时亦不过O(n)。
空间性能
空间总量渐进地不超过O(n^2)
6.4 邻接表
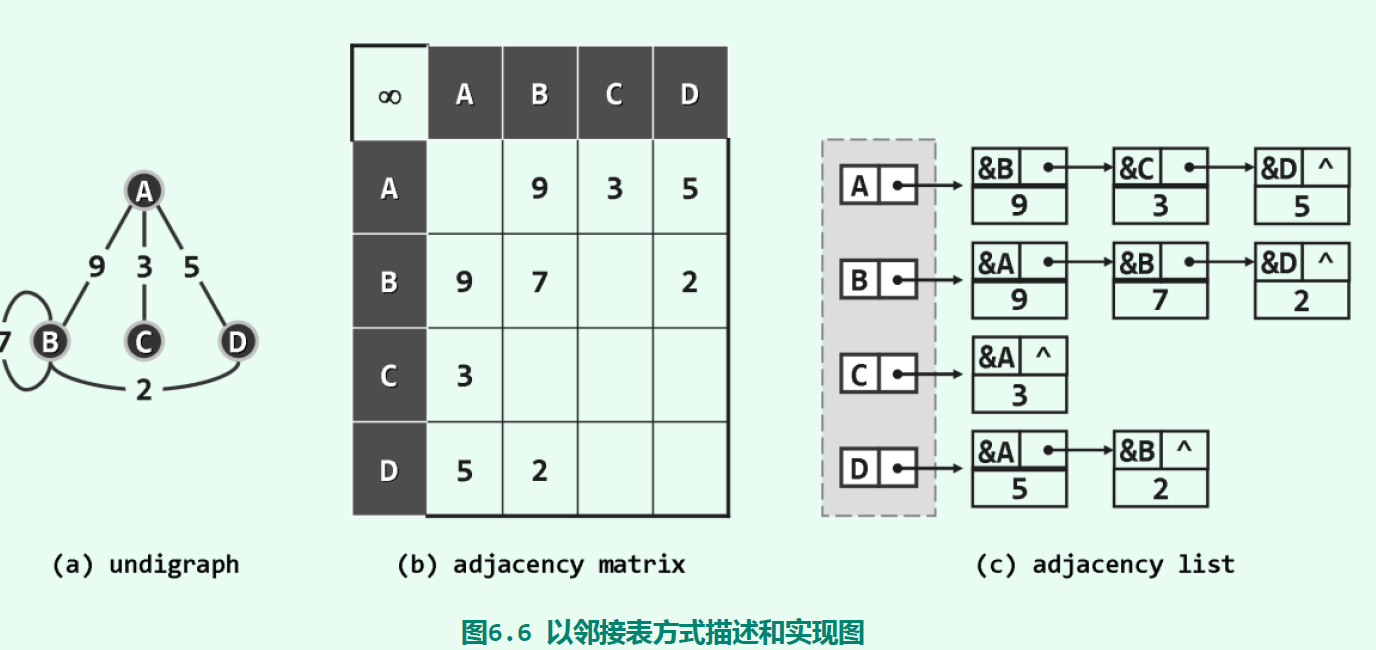
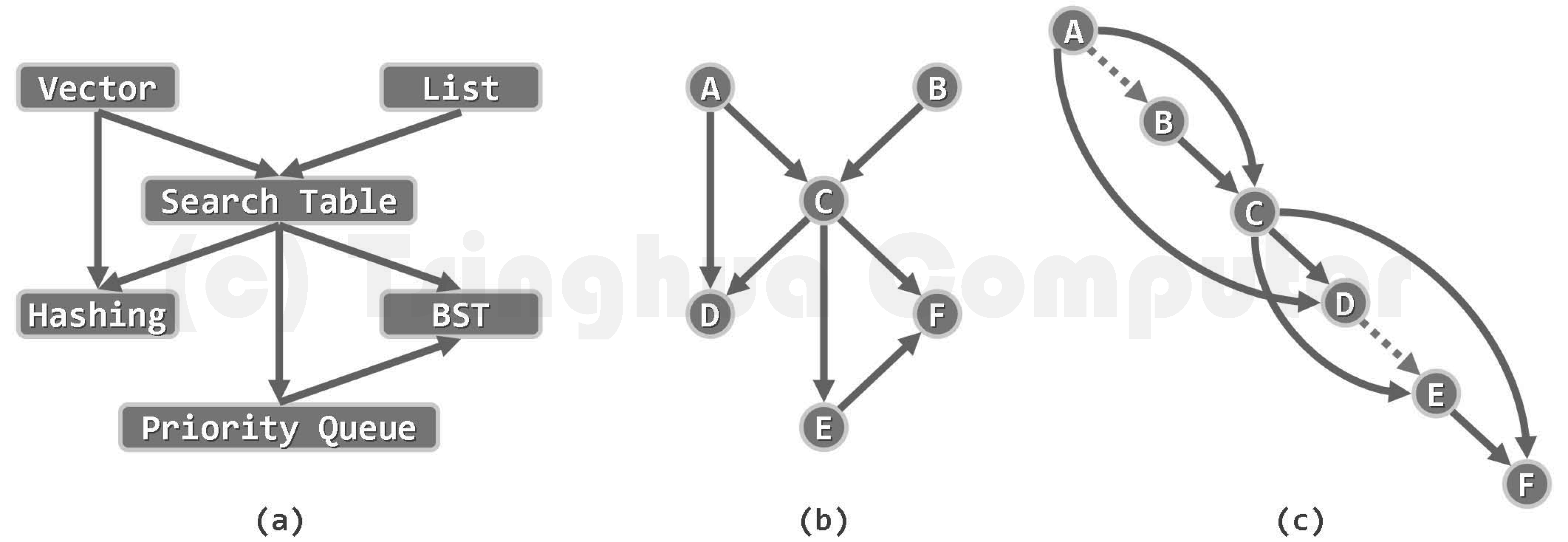
以如图6.6(a)所示的无向图为例,只需将如图(b)所示的邻接矩阵,逐行地转换为如图(c)所示的一组列表,即可分别记录各顶点的关联边(或等价地,邻接顶点)。这些列表,也因此称作邻接表(adjacency list)
邻接表效率较之邻接矩阵更高
6.5 图遍历算法概述
图的遍历也需要访问所有顶点一次且仅一次;此外,图遍历同时还需要访问所有的边一次且仅一次。
图的遍历都可理解为,将非线性结构转化为半线性结构的过程。经遍历而确定的边类型中,最重要的一类即所谓的树边,它们与所有顶点共同构成了原图的一棵支撑树(森林),称作遍历树(traversal tree)。以遍历树为背景,其余各种类型的边,也能提供关于原图的重要信息,比如其中所含的环路等。
图中顶点之间可能存在多条通路,故为避免对顶点的重复访问,在遍历的过程中,通常还要动态地设置各顶点不同的状态,并随着遍历的进程不断地转换状态,直至最后的“访问完毕”。图的遍历更加强调对处于特定状态顶点的甄别与查找,故也称作图搜索(graph search)。
诸如深度优先、广度优先、最佳优先等基本而典型的图搜索,都可以在线性时间内完成。准确地,若顶点数和边数分别为n和e,则这些算法自身仅需O(n + e)时。既然图搜索需要访问所有的顶点和边,故这已经是我们所能期望的最优的结果。
6.6 广度优先搜索
策略
同一顶点所有邻居之间的优先级,在多数遍历中不必讲究。因此,实质的差异应体现在,当有多个顶点已被访问到,应该优先从谁的邻居中选取下一顶点。
广度优先搜索(BFS)采用的策略,可以概括为,越早被访问到的顶点,其邻居越优先被选用。在所有已经访问到的顶点中,仍有邻居尚未访问者,构成所谓的波峰集 于是,BFS搜索过程也可以等效地理解为
反复从波峰集中找到最早被访问到顶点v,若其邻居均已访问到,则将其逐出波峰集;否则,随意选出一个尚未访问到的邻居,并将其加入到波峰集中若将上述BFS策略应用于树结构,则效果等同于层次遍历
实现
示例
算法的实质功能,由子算法BFS()完成。对该函数的反复调用,即可遍历所有连通或可达域。仿照树的层次遍历,这里也借助队列Q,来保存已被发现,但尚未访问完毕的顶点。因此,任何顶点在进入该队列的同时,都被随即标记为DISCOVERED(已发现)状态。
BFS()的每一步迭代,都先从Q中取出当前的首顶点v;再逐一核对其各邻居u的状态并做相应处理;最后将顶点v置为VISITED(访问完毕)状态,即可进入下一步迭代。
若顶点u尚处于UNDISCOVERED(未发现)状态,则令其转为DISCOVERED状态,并随即加入队列Q。实际上,每次发现一个这样的顶点u,都意味着遍历树可从v到u拓展一条边。于是,将边(v, u)标记为树边(tree edge),并按照遍历树中的承袭关系,将v记作u的父节点。 若顶点u已处于DISCOVERED状态(无向图),或者甚至处于VISITED状态(有向图),则意味着边(v, u)不属于遍历树,于是将该边归类为跨边(cross edge)(习题6-11])。 BFS()遍历结束后,所有访问过的顶点通过parent[]指针依次联接,从整体上给出了原图某一连通或可达域的一棵遍历树,称作广度优先搜索树,或简称BFS树(BFS tree)。
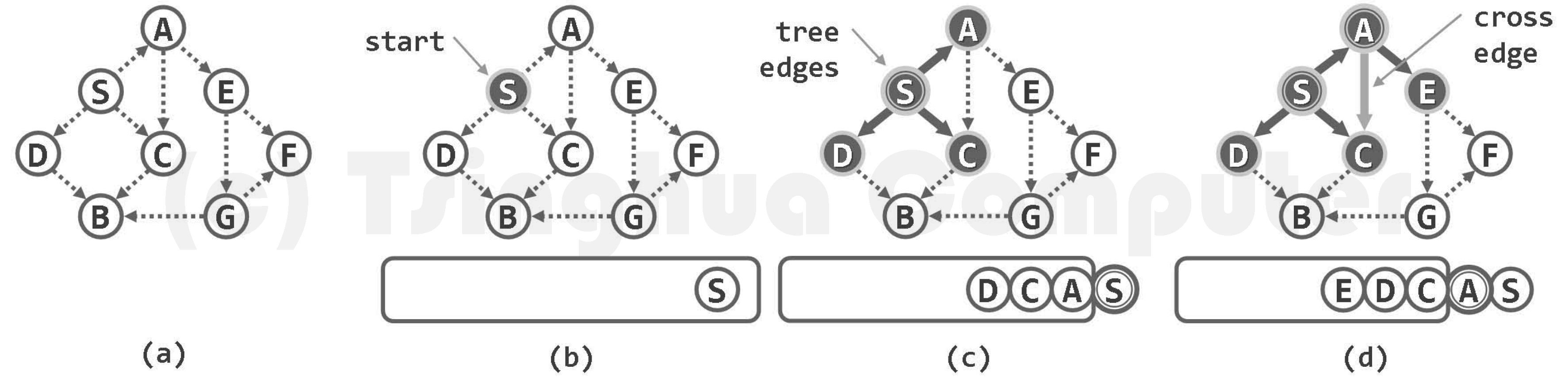
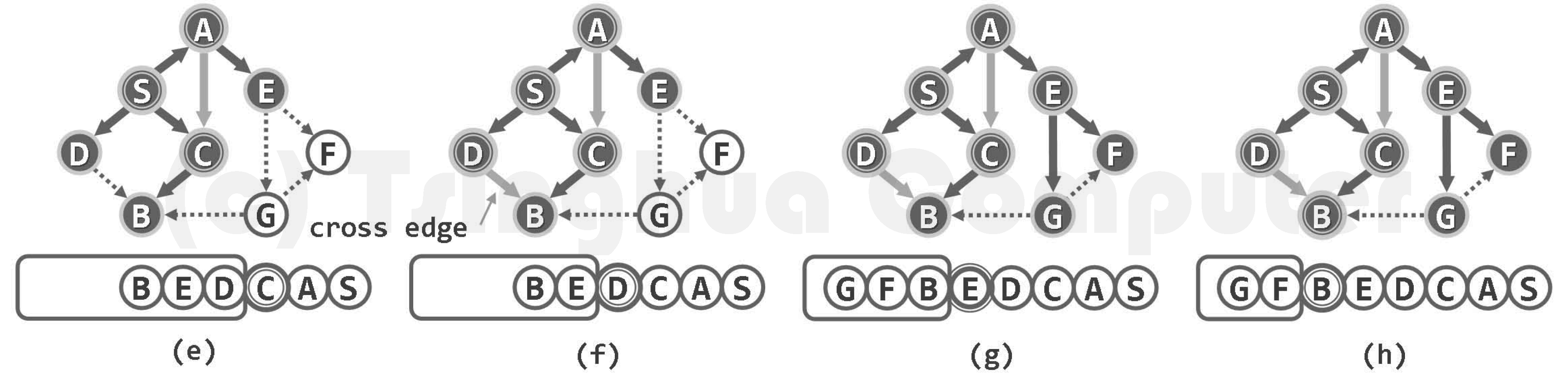
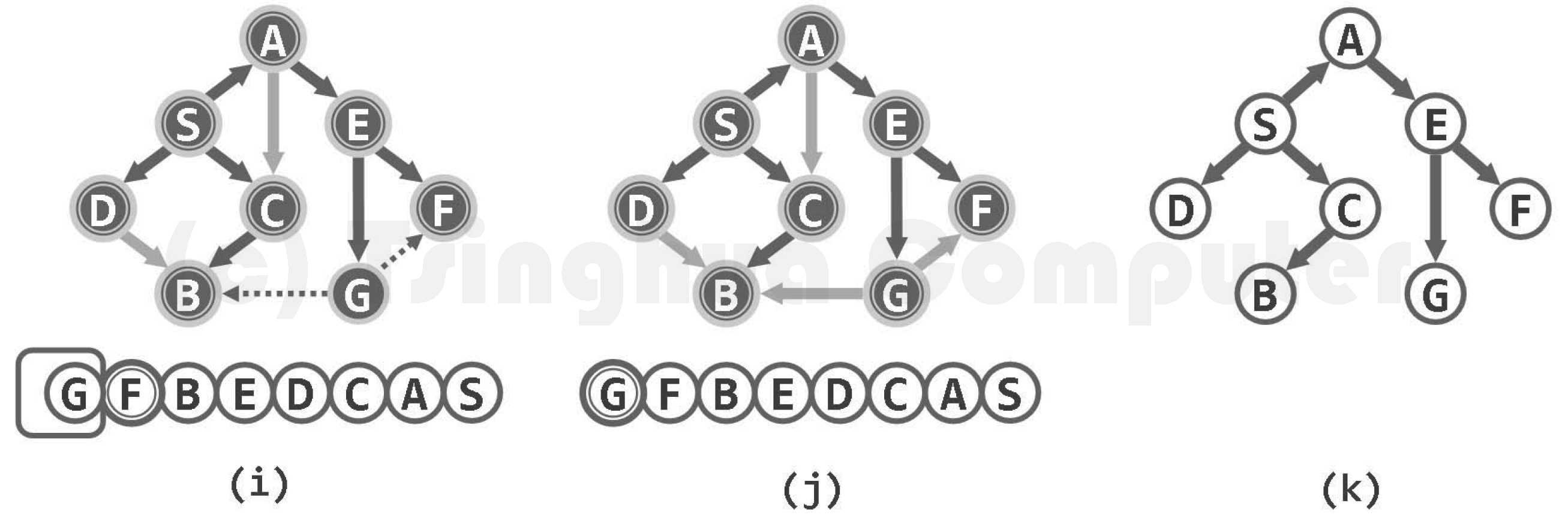
如此,各次BFS()调用所得的BFS树构成一个森林,称作BFS森林(BFS forest)。
复杂度
空间,主要消耗在用于维护顶点访问次序的辅助队列、用于记录顶点和边状态的标识位向量,累计O(n) + O(n) + O(e) = O(n + e)。
时间方面,首先需花费O(n + e)时间复位所有顶点和边的状态。不计对子函数BFS()的调用,bfs()本身对所有顶点的枚举共需O(n)时间。而在对BFS()的所有调用中,每个顶、每条边均只耗费O(1)时间,累计O(n + e)。综合起来,BFS搜索总体仅需O(n + e)时间。
应用
基于BFS搜索,可以有效地解决 连通域问题、最短路径问题
6.7 深度优先搜索
策略
深度优先搜索(DFS),可以概括为
优先选取最后一个被访问到的顶点的邻居于是,以顶点s为基点的DFS搜索,将首先访问顶点s;再从s所有尚未访问到的邻居中任取其一,并以之为基点,递归地执行DFS搜索。故各顶点被访问到的次序,类似于树的先序遍历(5.4.2节);而各顶点被访问完毕的次序,则类似于树的后序遍历
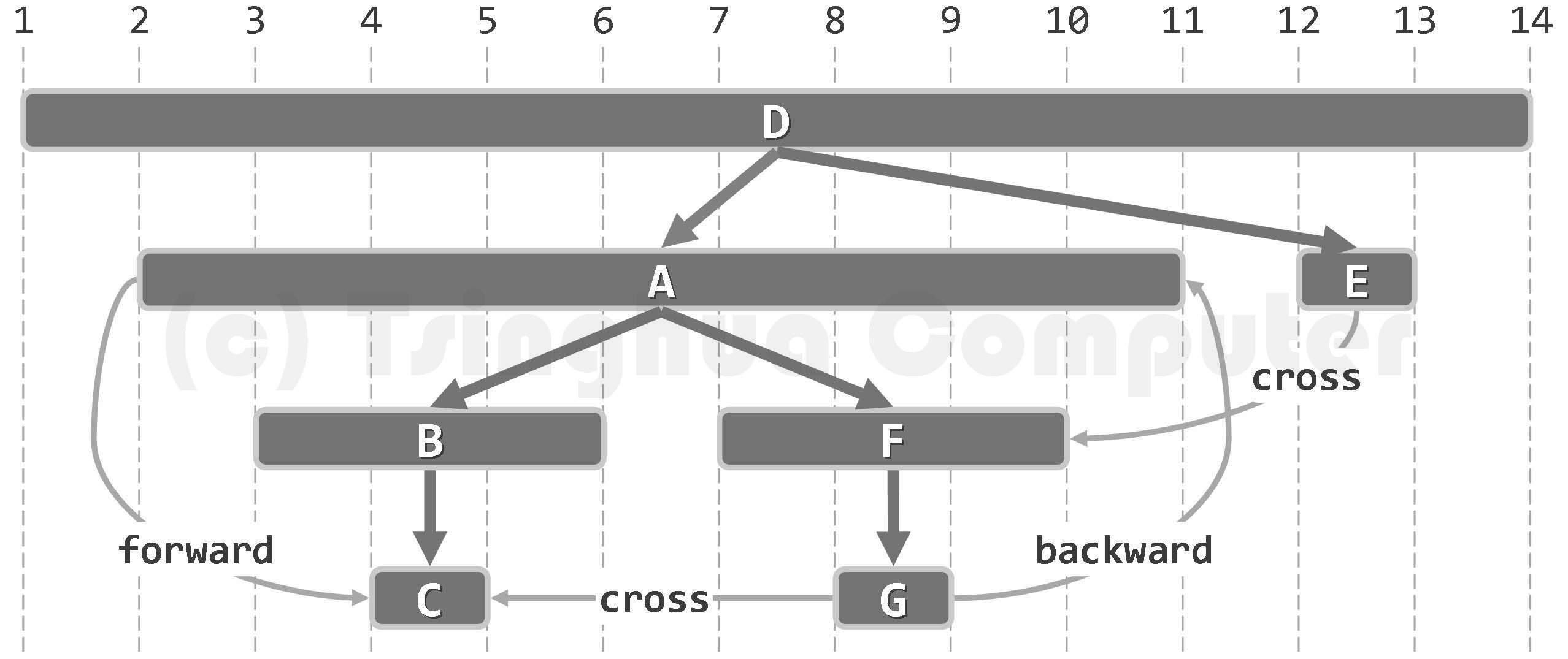
算法的实质功能,由子算法DFS()递归地完成。每一递归实例中,都先将当前节点v标记为DISCOVERED(已发现)状态,再逐一核对其各邻居u的状态并做相应处理。待其所有邻居均已处理完毕之后,将顶点v置为VISITED(访问完毕)状态,便可回溯。
若顶点u尚处于UNDISCOVERED(未发现)状态,则将边(v, u)归类为树边(tree edge),
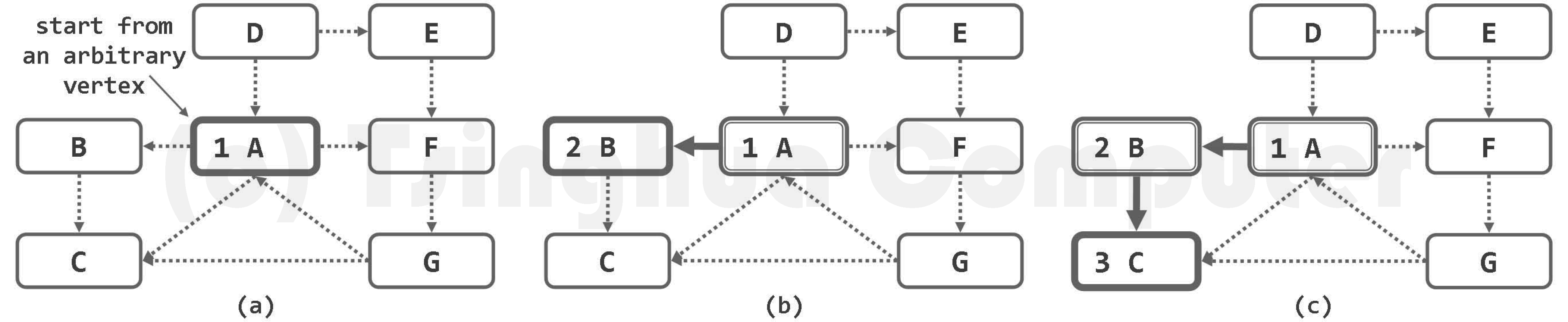
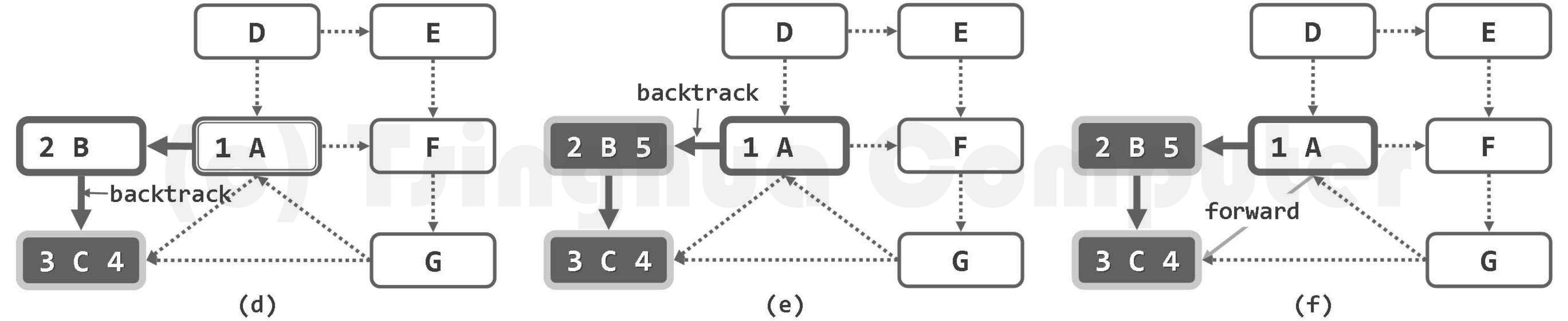
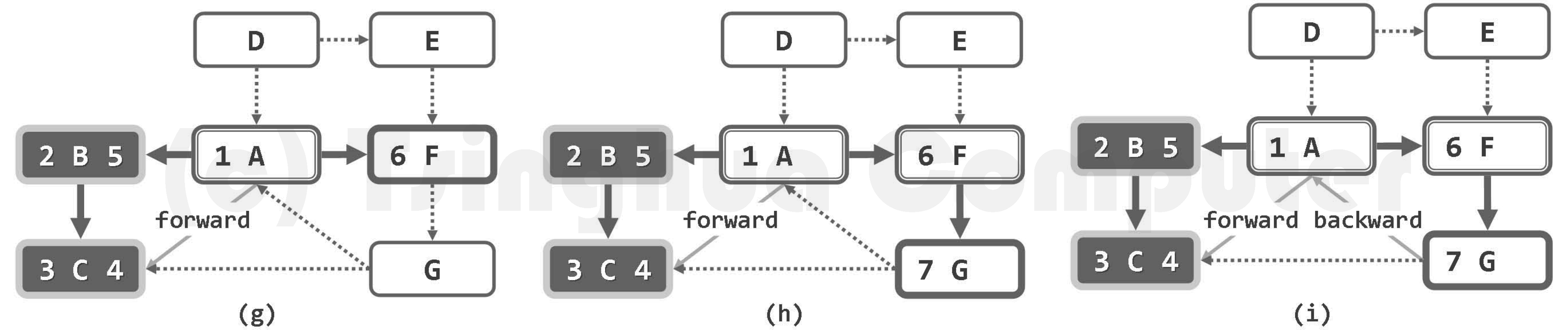
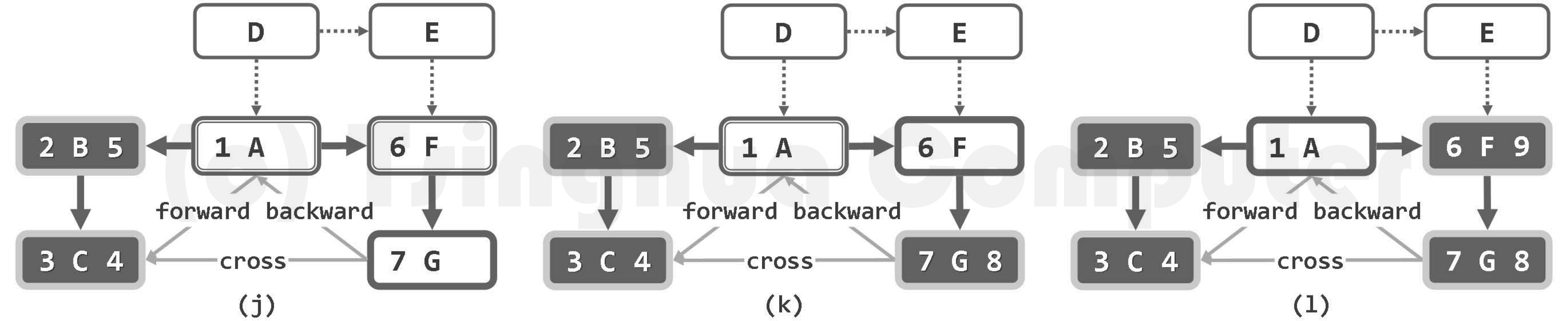
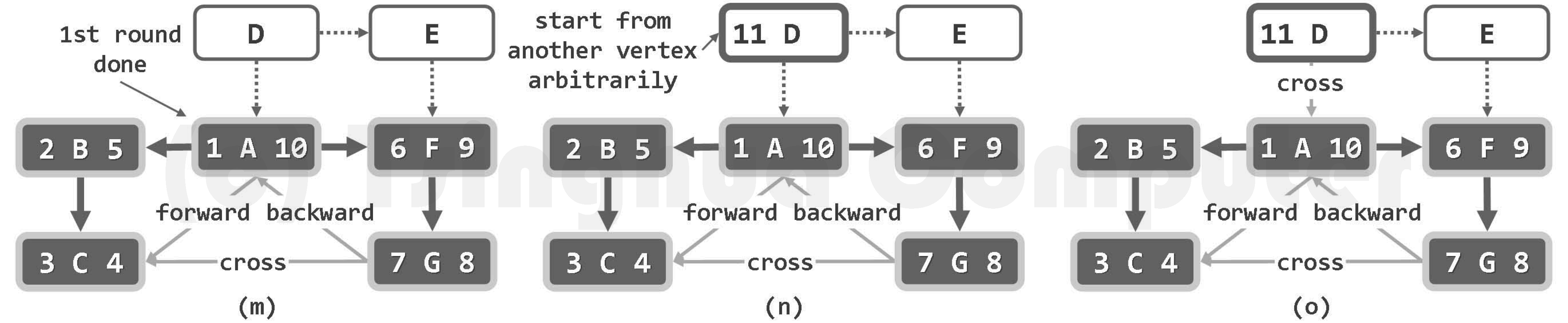
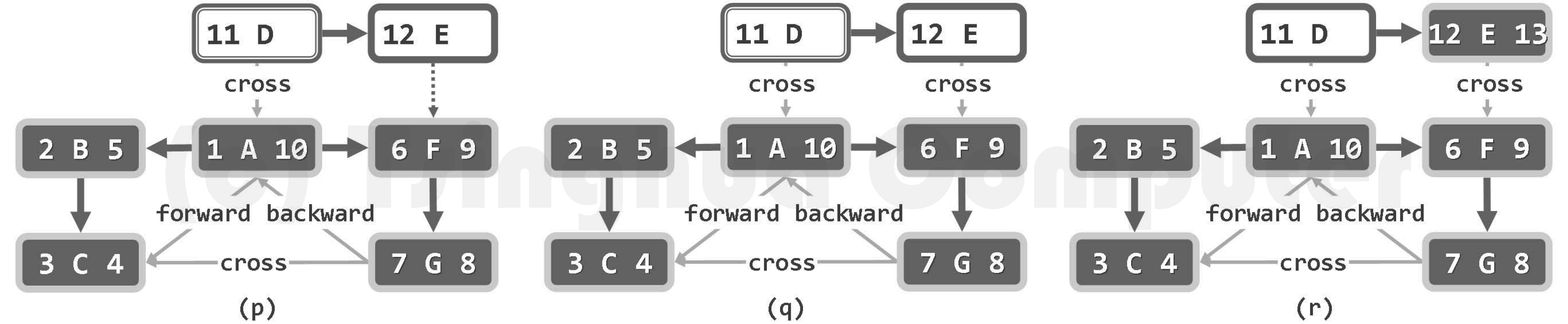
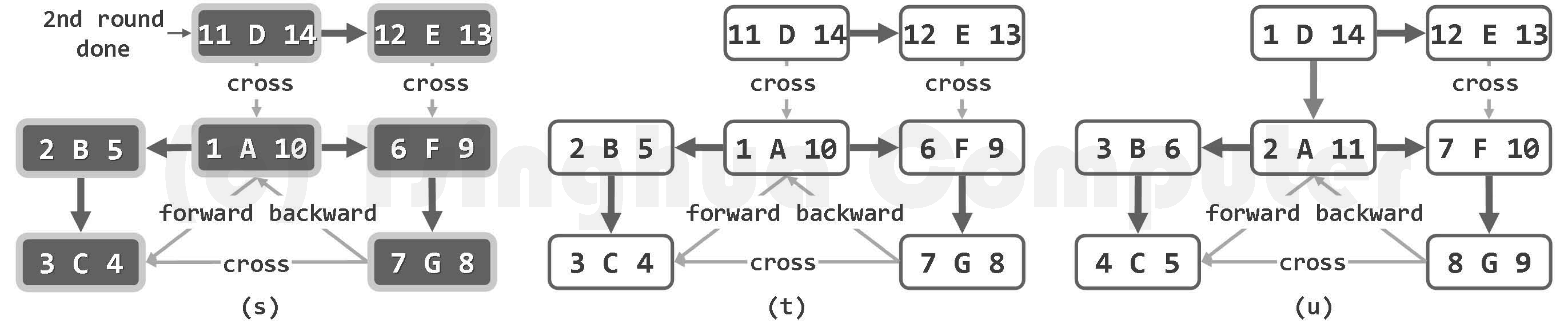
粗边框白色,为当前顶点;细边框白色、双边框白色和黑色,分别为处于UNDISCOVERED、DISCOVERED和VISITED状态的顶点;dTime和fTime标签,分删标注于各顶点的左右)
最终结果如图(t)所示,为包含两棵DFS树的一个DFS森林。可以看出,选用不同的起始基点,生成的DFS树(森林)也可能各异。如本例中,若从D开始搜索,则DFS森林可能如图(u)所示。图6.9 以时间为横坐标, 绘出了图6.8(u)中DFS树内各顶点的活跃期。可以清晰地看出,活跃期相互包含的顶点,在DFS树中都是“祖先-后代”关系(比如B之于C, 或者D之于F);反之亦然。 这种对应关系并非偶然,籍此可以便捷地判定节点之间的承袭关系。故无论是对DFS搜索本身,还是对基于DFS的各种算法而言,时间标签都至关重要。
复杂度
可以在O(n+e)时间内完成
应用
以拓扑排序和双连通域分解为例,对DFS模式的应用做更具体的介绍
6.8 拓扑排序
应用
拓扑排序一个实例
实际上,许多应用问题,都可转化和描述为这一标准形式:给定描述某一实际应用(图(a))的有向图(图(b)),如何在与该图“相容”的前提下,将所有顶点排成一个线性序列(图(c))。此处的“相容”,准确的含义是:每一顶点都不会通过边,指向其在此序列中的前驱顶点。这样的一个线性序列,称作原有向图的一个拓扑排序(topological sorting)。
有向无环图
有向无环图的拓扑排序必然存在;反之亦然。这是因为,有向无环图对应于偏序关系,而拓扑排序则对应于全序关系。在顶点数目有限时,与任一偏序相容的全序必然存在。 任一有限偏序集,必有极值元素(尽管未必唯一);类似地,任一有向无环图,也必包含入度为零的顶点。否则,每个顶点都至少有一条入边,意味着要么顶点有无穷个,要么包含环路。 于是,只要将入度为0的顶点m(及其关联边)从图G中取出,则剩余的G’依然是有向无环图,故其拓扑排序也必然存在。从递归的角度看,一旦得到了G’的拓扑排序,只需将m作为最大顶点插入,即可得到G的拓扑排序。如此,我们已经得到了一个拓扑排序的算法

算法
同理,有限偏序集中也必然存在极小元素(同样,未必唯一)。该元素作为顶点,出度必然为零–比如图6.10(b)中的顶点D和F。而在对有向无环图的DFS搜索中,首先因访问完成而转换至VISITED状态的顶点m,也必然具有这一性质;反之亦然。 进一步地,根据DFS搜索的特性,顶点m(及其关联边)对此后的搜索过程将不起任何作用。于是,下一转换至VISITED状态的顶点可等效地理解为是,从图中剔除顶点m(及其关联边)之后的出度为零者—在拓扑排序中,该顶点应为顶点m的前驱。由此可见,DFS搜索过程中各顶点被标记为VISITED的次序,恰好(按逆序)给出了原图的一个拓扑排序。 此外,DFS搜索善于检测环路的特性,恰好可以用来判别输入是否为有向无环图。具体地,搜索过程中一旦发现后向边,即可终止算法并报告“因非DAG而无法拓扑排序”。